Similarity computation¶
Let’s consider two binaries (or attributed graphs), a primary with 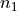 functions
(or nodes) and a secondary with
functions
(or nodes) and a secondary with 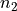 functions (or nodes).
functions (or nodes).
As we described previously, the similarity between the nodes of the two input graphs is one of the
two required information for QBinDiff. We can think of it as a function that takes in input two
nodes, one belonging to the primary and the other belonging to the secondary, and returns
a normalized value between ![[0, 1]](../../../_images/math/8027137b3073a7f5ca4e45ba2d030dcff154eca4.png) that represents how similar the two nodes are, only
considering the node attributes.
that represents how similar the two nodes are, only
considering the node attributes.
![f \colon G_1 \times G_2 \longrightarrow [0, 1]](../../../_images/math/a271a8d966deac7a98a89656d22a9b0b6aecae77.png)
In practice, the function is implemented as a matrix 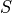 of shape
of shape 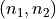 where
the value
where
the value 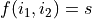 is stored at position
is stored at position ![[i_1, i_2]](../../../_images/math/a63adae8d588c414ef6160fbba5eff55454e5a20.png) in the matrix .
in the matrix .
Note
From now on, without loss of generality, we are going to refer only to the similarity matrix, without ever mentioning the function 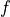 .
.
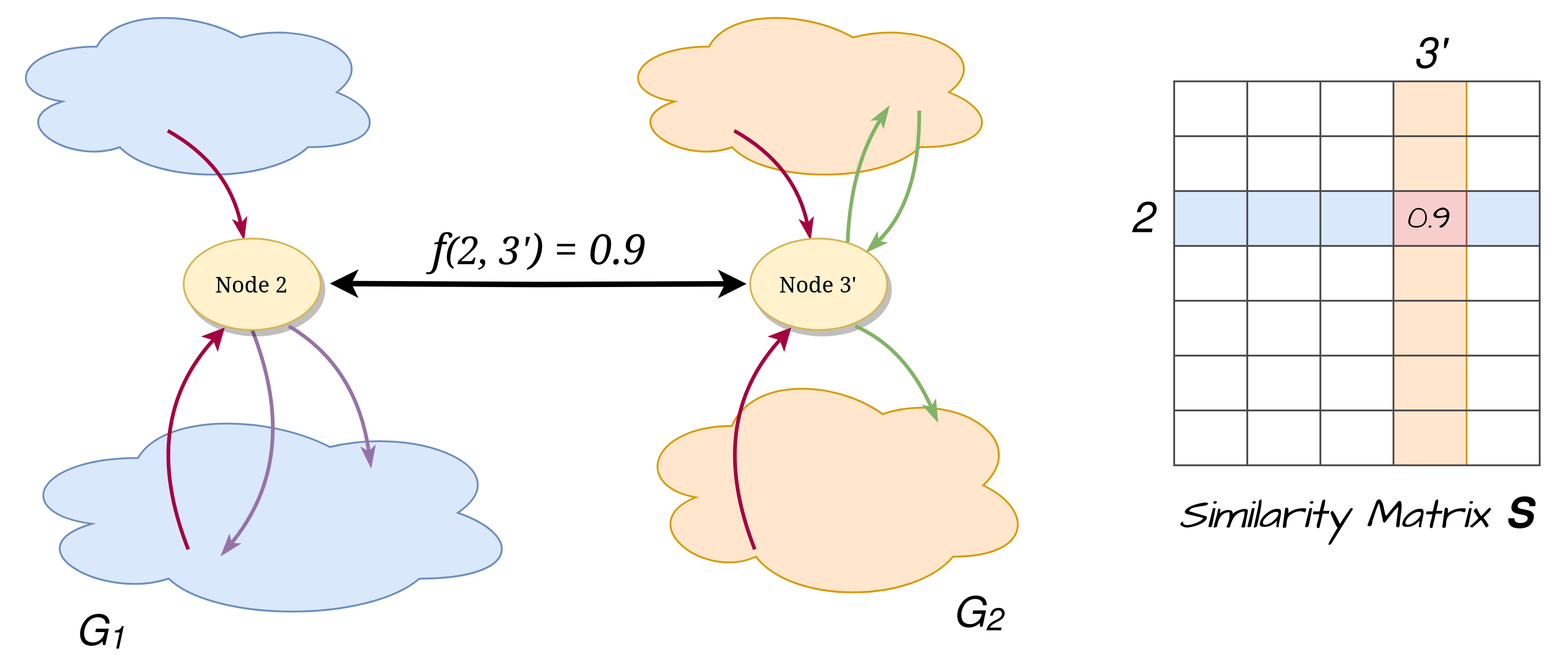
In order to keep the most versatility, in QBinDiff, the similarity matrix can be partially or totally user supplied through the pass refinement system. This is a system of callbacks that the user can register with the aim of refining the values in the similarity matrix by using any kind of user defined property. This becomes particularly useful when dealing with a problem instance that is not related to binary diffing but that still handles attributed graphs.
For the problem of binary diffing, instead, there is already a set of heuristics that can be used to populate the similarity matrix. These heuristics are called features as they characterize the functions by extracting some information or features.
Features¶
Features are heuristics that operate at specific level inside the function (operand, instruction, basic block, function) to compute a feature vector. You can also think of feature vectors as a way of compressing the information that was extracted in a mathematical object. This information should help to characterize the function. It is an embedding of the function.
An example of a feature heuristic can be counting how many basic blocks are there in the function Control Flow Graph (CFG), we can arguably say that similar functions should have more or less the same number of blocks and by using that heuristic (or feature) we can give a score on how similar two functions are.
QBinDiff provides a lot of features an user can choose to compute the similarity. Indeed, relevant features for diffing is task-dependent and a feature may be very useful for specific diffing and useless in others. For example, the “basic blocks number” feature is useful only when we assume similar functions have the same number of blocks. If our assumption is false, namely, that two functions have been compiled with different optimization techniques or that have been obfuscated, then the heuristic will produce irrelevant results.
In order to provide the user even better control over the entire process, it’s possible to specify weights for the features in order to make some of them more important in the final evaluation of the similarity.
Some of these features comes from or are inspired by other differs, such as BinDiff or Diaphora.
Warning
Always keep in mind what the underlying assumptions of the features you are using are. If they don’t hold in your specific context, you might end up with bad results.
All the QBinDiff features are listed here, from the larger granularity to the smallest one.
Outside function-level features¶
ChildNb: Number of function child of the current function inside the Function Call Graph.ParentNb: Number of function parents of the current function inside the Function Call Graph.RelativeNb: Sum of the features ChildNb and ParentNbLibName: Dictionary with the addresses of children function as key and the number of time these children are called if they are library functionsImpName: Dictionary with the addresses of children function as key and the number of time these children are called if they are imported functions
Inside function-level features¶
BBlockNb: Number of basic blocks inside the function. Two functions that come from the same source code but that are compiled differently may have a different number of basic blocks.StronglyConnectedComponents: Number of strongly connected components inside the Function Call Graph.BytesHash: Hash of the function, using the instructions sorted by addresses. Two functions that come from the same source code but that are compiled differently will probably have a different hash.CyclomaticComplexity: Uses the cyclomatic complexity metric.MDIndex: This feature is based on previous work of Dullien et al.. It is slightly modified : indeed, the topological sort is only available for Directed Acyclic Graphs (DAG).SmallPrimeNumbers: Small-Prime-Number hash, based on mnemonics, based on previous work of Dullien et al.. It is slightly modified from the theoretical implementation. The modulo is made at each round for computational reasons, not only at the end. [TODO:check the validity of the formula with Z3 (again)]MaxParentNb: Maximum number of predecessors per basic block in the flowgraph.MaxChildNb: Minimum number of predecessors per basic block in the flowgraph.MaxInsNB: Maximum number of basic blocks instructions in the function.MeanInsNB: Mean number of basic blocks instructions in the function.InstNB: Number of instructions in the whole function.GraphMeanDegree: Mean degree of the function flowgraph.GraphDensity: Density of the function flowgraph.GraphNbComponents: Number of components of the (undirected) function flowgraph. This feature should be almost all the time set to 1. Otherwise, this mean two.GraphDiameter: Diameter of the function flowgraph.GraphTransitivity: Transitivity of the function flowgraph.GraphCommunities: Number of graph communities of the (undirected) function flowgraph.Address: Address of the function. This feature will not be robust against different compilation options.FuncName: Name of the function. This feature will not be robust against several obfuscation techniques.WeisfeilerLehman: This feature applies a Weisfeiler Lehman kernel combined with a Local Sensitive Hashing as labeling function. This feature derives from a Quarkslab blogpost.
Warning
The WeisfeilerLehman feature suffers from several drawbacks, both theoretically and in term of implementation. It may cause some numerical instability errors depending on your binaries. This feature may be refactor in a near future.
Basic-block level features¶
/
Instruction level features¶
PcodeMnemonicSimple: Bag-of-word dictionary counting the pcode operands mnemonic.MnemonicSimple: TODO write descriptionMnemonicTyped: TODO write descriptionGroupsCategory: TODO write descriptionDatName: TODO write descriptionStrRef: TODO write descriptionJumpNb: Number of jump in the whole function.
Operand level features¶
Constant: TODO write descriptionReadWriteAccess: Number of Read and Write Access to the memory. This feature should be resistant to some obfuscation techniques and compilation options.
How to choose features ?¶
Choosing features can be tedious depending on the binary under hand.
In general, enabling all the features will give satisfiable results. However, in some cases, feature fine-tuning can be necessary. These cases are numerous and we do not cover all of them.
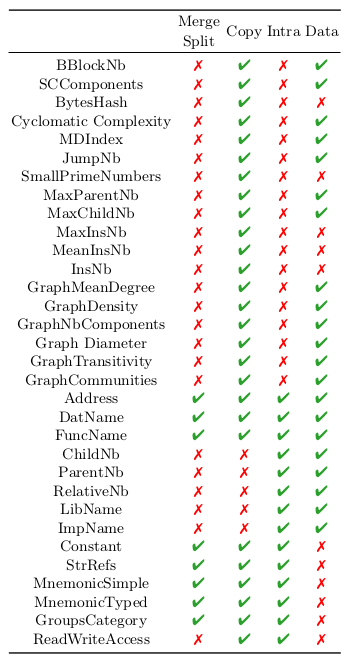
We provide a list of features that should be used when either the primary or the secondary (or both) are suspected to be obfuscated. Depending on the suspected obfuscation, specific features should be chosen.
Here are the different obfuscation techniques considered in the table below:
Split refers to the inter-procedural Split obfuscation, that breaks a function into different chunks.
Merge obfuscation is also an inter-procedural obfuscation that consists of merging different functions together.
Copy obfuscation (inter-procedural) creates a clone of a given function.
Data obfuscations refer to any obfuscation that modifies the data-flow (such as Mixed Boolean Arithmetic or MBA).
Intra obfuscations refer to any obfuscation that modifies the function controlflow (such as Controlflow-Graph Flattening or CFF).
For example, if an intra-procedural obfuscation, such as the Controlflow Graph Flattening, is suspected to be applied on a binary (Controlflow Graph Flattening exhibits a very specific pattern), then the Cyclomatic Complexity will not be a feature that will lead to better diffing results, whereas the MnemonicSimple probably will.